
fastplotlib

greptimedb


| fastplotlib | greptimedb | |
|---|---|---|
| 2 | 17 | |
| 343 | 3,905 | |
| 5.5% | 4.1% | |
| 8.9 | 9.9 | |
| 7 days ago | 6 days ago | |
| Python | Rust | |
| Apache License 2.0 | Apache License 2.0 |
Stars - the number of stars that a project has on GitHub. Growth - month over month growth in stars.
Activity is a relative number indicating how actively a project is being developed. Recent commits have higher weight than older ones.
For example, an activity of 9.0 indicates that a project is amongst the top 10% of the most actively developed projects that we are tracking.
fastplotlib
-
Emerging Rust GUI libraries in a WASM world
https://github.com/kushalkolar/fastplotlib
Alternatively, try pygfx for ThreeJS graphics in Python leveraging wgpu. It works great in Notebooks through notebook-rfb. https://github.com/pygfx/pygfx
If you're adventurous, figure out how to make pygfx work with webgpu via wasm
-
Extending Python with Rust
Rather than using matplotlib, you could try either pygfx (https://github.com/pygfx/pygfx) or fastplotlib (https://github.com/kushalkolar/fastplotlib) to make higher performance graphics using Python.
However, it won't solve your problem of Python not being fast enough doing the calculations.
greptimedb
-
Error Handling for Large Rust Projects - A Deep Dive into GreptimeDB's Practices
**A good error report is not only about how it gets constructed, but what is more important, to tell what human can understand from its cause and trace. We call it Stacked Error.** It should be intuitive and you must have seen a similar format elsewhere like backtrace. From this log, it's easy to know the entire thing with full context, from the user-facing behavior to the root cause. Plus the exact line and column number of where each error is propagated. You will know that this error is *"from the query "blabla", the fifth package's header is corrupted"*. It's likely to be invalid user input and we may not need to handle it from the server side. This example shows the critical information that an error should contain: - **The root cause** that tells what is happening. - **The full context stack** that can be used in debugging or figuring out where the error occurs. - **What happens from the user's perspective.** Decide whether we need to expose the error to users. The first root cause is often clear in many cases, like the DecodeMessage example above, as long as the library or function we used implements their error type correctly. But only having the root cause can be not enough. Here is another [evidence](https://github.com/delta-incubator/delta-kernel-rs/pull/151) from Delta Lake developed by Databricks: 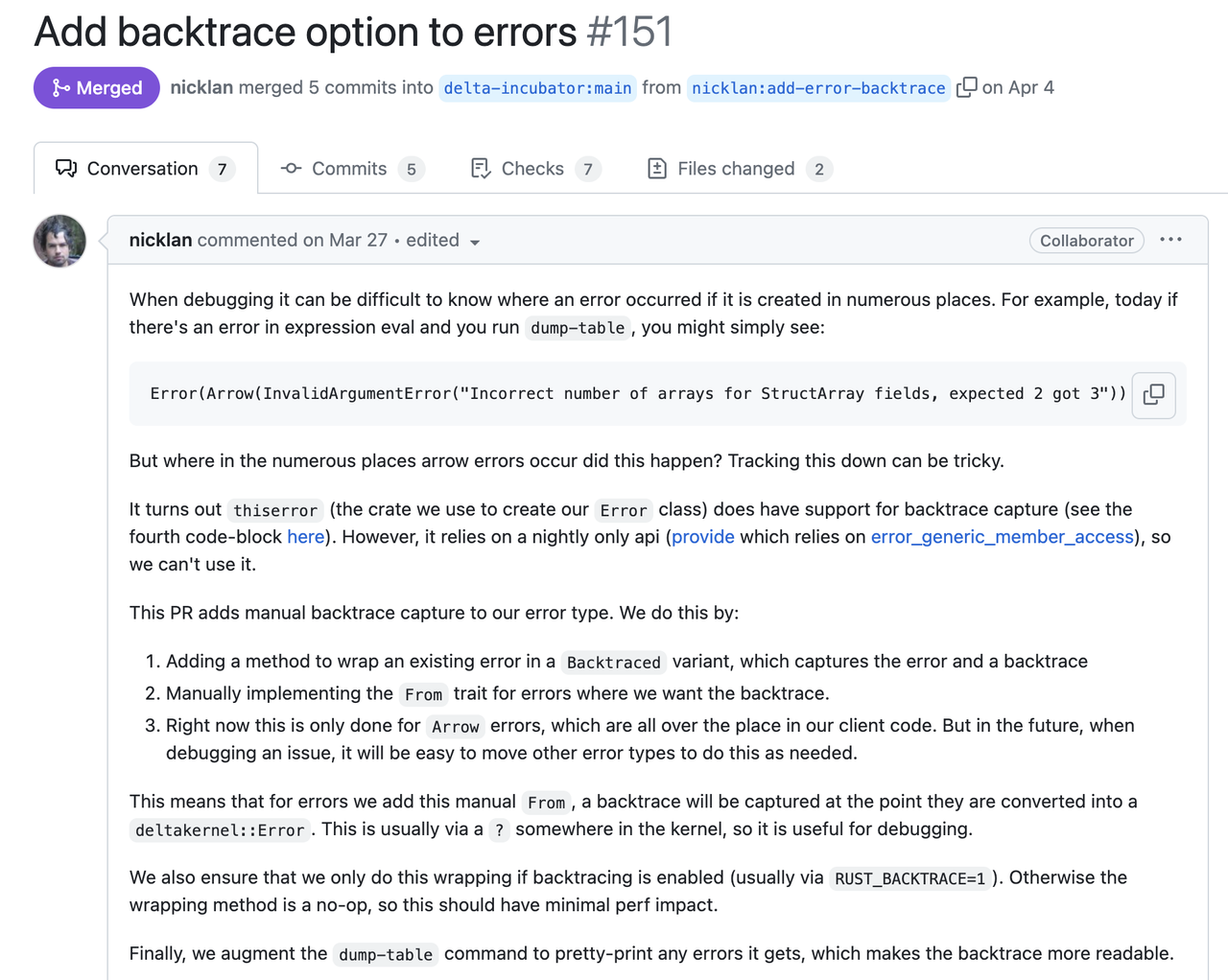 In the following sections, we will focus on the context stack and the way to present errors. And shows the way we implement it. So hopefully you can reproduce the same practices as in GreptimeDB. ### System Backtrace So, now you have the root cause (`DecodeMessage(serde_json: invalid character at 1)`). But it's not clear at which step this error occurs: when decoding the header, or the body? A intuitive thought is to capture the backtrace. `.unwrap()` is the first choice, where the backtrace will show up when error occurs (of course this is a bad practice). It will give you a complete call stack along with the line number. Such a call stack contains the full trace, including lots of unrelated system stacks, runtime stacks and std stacks. If you'd like to find the call in application code, you have to inspect the source code stack by stack, and skip all the unrelated ones. Nowadays, many libraries also provide the ability to capture backtrace on an `Error` is constructed. Regardless of whether the system backtrace can provide what we truly want, it's very costly on either CPU ([#1261](https://github.com/GreptimeTeam/greptimedb/pull/1261)) and memory ([#1273](https://github.com/GreptimeTeam/greptimedb/pull/1273)). Capturing a backtrace will significantly slow down your program, as it needs to walk through the call stack and translate the pointer. Then, to be able to translate the stack pointer we will need to include a large `debuginfo` in our binary. In GreptimeDB, this means increasing the binary size by >700MB (4x compared to 170MB without debuginfo). And there will be many noises in the captured system backtrace because the system can't distinguish whether the code comes from the standard library, a third-party async runtime or the application code. There is another difference between the system backtrace and the proposed Stacked Error. System backtrace tells us how to get to the position where the error occurs and you cannot control it, while the Stacked Error shows how the error is propagated. Take the following code snippet as an example to examine the difference between system backtrace and virtual stack: ```rust async fn handle_request(req: Request) -> Result { let msg = decode_msg(&req.msg).context(DecodeMessage)?; // propagate error with new stack and context verify_msg(&msg)?; // pass error to the caller directly process_msg(msg).await? // pass error to the caller directly } async fn decode_msg(msg: &RawMessage) -> Result { serde_json::from_slice(&msg).context(SerdeJson) // propagate error with new stack and context }
- GreptimeDB: A fast and cost-effective alternative to InfluxDB
- Another distributed time-series database written in Rust
-
GreptimeAI + Xinference - Efficient Deployment and Monitoring of Your LLM Applications
GreptimeAI, built upon the open-source time-series database GreptimeDB, offers an observability solution for Large Language Model (LLM) applications, currently supporting both LangChain and OpenAI's ecosystem. GreptimeAI enables you to understand cost, performance, traffic and security aspects in real-time, helping teams enhance the reliability of LLM applications.
-
What's everyone working on this week (49/2023)?
Continuing to work hard on a new MetricEngine in GreptimeDB. BTW, If you have a keen interest in Rust or database development, GreptimeDB might be a good starting point. Check it out for some good first issues here.
-
Practical Tips for Refactoring Release CI using GitHub Actions
Since the very first day of GreptimeDB going open-source, it embraced the automated software building process with GitHub Actions, and leading to the inaugural Release Pipeline.
-
GreptimeCloud - A Fully Managed Serverless Prometheus Backend
Born from the open-source project GreptimeDB, GreptimeCloud serves as a fully-managed, serverless cloud backend for Prometheus, offering integrated support for remote read/write protocols and PromQL as one of our primary query languages.
-
Bridging Async and Sync Rust Code - A lesson learned while working with Tokio
Recently, while working on our GreptimeDB project, we encountered an issue with calling asynchronous Rust code in a synchronous context.
-
A Deep Dive into PromQL — Promql Parser v0.1.0 Written in Rust is Now Available
To explore data stored in GreptimeDB through PromQL, GreptimeDB needs to provide the ability to parse the query into AST (abstract syntax tree), and retrieve data from memory or disk via logical and physical plans. Since there is no ready-to-use PromQL Rust Parser, our team decides to develop it by ourselves. We’re glad to announce that promql-parser v0.1.0 is now available.
What are some alternatives?
graphics_wgpu
risingwave - SQL stream processing, analytics, and management. We decouple storage and compute to offer instant failover, dynamic scaling, speedy bootstrapping, and efficient joins.
vswhere - Locate Visual Studio 2017 and newer installations
cnosdb - A cloud-native open source distributed time series database with high performance, high compression ratio and high availability. http://www.cnosdb.cloud
pygfx - Powerful and versatile visualization for Python.
FlashDB - An ultra-lightweight database that supports key-value and time series data | 一款支持 KV 数据和时序数据的超轻量级数据库
python-qubit-setup - All scripts for controlling the instruments and acquiring data in our qubit setup.
datafuse - An elastic and reliable Cloud Warehouse, offers Blazing Fast Query and combines Elasticity, Simplicity, Low cost of the Cloud, built to make the Data Cloud easy [Moved to: https://github.com/datafuselabs/databend]
Numba - NumPy aware dynamic Python compiler using LLVM
numexpr - Fast numerical array expression evaluator for Python, NumPy, Pandas, PyTables and more
silkenweb - A library for writing reactive single page web apps
corrosion - Gossip-based service discovery (and more) for large distributed systems.