

















SaaSHub helps you find the best software and product alternatives Learn more →
Top 23 Rust SQL Projects
-
-
-
InfluxDB
Power Real-Time Data Analytics at Scale. Get real-time insights from all types of time series data with InfluxDB. Ingest, query, and analyze billions of data points in real-time with unbounded cardinality.

-
-
sqlx
🧰 The Rust SQL Toolkit. An async, pure Rust SQL crate featuring compile-time checked queries without a DSL. Supports PostgreSQL, MySQL, and SQLite. (by launchbadge)
-
prql
PRQL is a modern language for transforming data — a simple, powerful, pipelined SQL replacement
-
databend
𝗗𝗮𝘁𝗮, 𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀 & 𝗔𝗜. Modern alternative to Snowflake. Cost-effective and simple for massive-scale analytics. https://databend.com
-
risingwave
SQL stream processing, analytics, and management. We decouple storage and compute to offer speedy bootstrapping, dynamic scaling, time-travel queries, and efficient joins.
-
SaaSHub
SaaSHub - Software Alternatives and Reviews. SaaSHub helps you find the best software and product alternatives

-
-
-
postgresml
The GPU-powered AI application database. Get your app to market faster using the simplicity of SQL and the latest NLP, ML + LLM models.
-
-
readyset
Readyset is a MySQL and Postgres wire-compatible caching layer that sits in front of existing databases to speed up queries and horizontally scale read throughput. Under the hood, ReadySet caches the results of cached select statements and incrementally updates these results over time as the underlying data changes.
-
greptimedb
An open-source, cloud-native, distributed time-series database with PromQL/SQL/Python supported. Available on GreptimeCloud.
-
-
-
GQL
Git Query language is a SQL like language to perform queries on .git files with supports of most of SQL features such as grouping, ordering and aggregations functions
-
-
-
-
SaaSHub
SaaSHub - Software Alternatives and Reviews. SaaSHub helps you find the best software and product alternatives
Project mention: Why SurrealDB is the Future of Database Technology - An In-Depth Look | dev.to | 2024-05-09SurrealDB was designed from the start to have unparalleled deployment flexibility, combining the ease of use of embedded databases such as SQLite and the power of client-server databases with all our multi-model features into a single Rust binary!
Project mention: MQL – Client and Server to query your DB in natural language | news.ycombinator.com | 2024-04-07I should have clarified. There's a large number of apps that are:
1. taking info strictly from SQL (e.g. information_schema, query history)
2. taking a user input / question
3. writing SQL to answer that question
An app like this is what I call "text-to-sql". Totally agree a better system would pull in additional documentation (which is what we're doing), but I'd no longer consider it "text-to-sql". In our case, we're not even directly writing SQL, but rather generating semantic layer queries (i.e. https://cube.dev/).
Project mention: Top 10 Rusty Repositories for you to start your Open Source Journey | dev.to | 2023-12-197. Diesel
For PostgreSQL, the most relevent part of the code is here. With this in mind I changed some things around to rely on schemas instead of databases and even simplified some parts of the implementation as this was always meant to be for internal use only..
Project mention: Prolog language for PostgreSQL proof of concept | news.ycombinator.com | 2024-03-30
Databend vs. Snowflake: https://github.com/datafuselabs/databend/issues/13059
Project mention: Proton, a fast and lightweight alternative to Apache Flink | news.ycombinator.com | 2024-01-30How does this compare to RisingWave and Materialize?
https://github.com/risingwavelabs/risingwave
SQL with SeaORM:
Project mention: The Notifier Pattern for Applications That Use Postgres | news.ycombinator.com | 2024-05-14Those updates are not retroactive. They apply on a go forward basis. Each day's changes become Apache 2.0 licensed on that day four years in the future.
For example, v0.28 was released on October 18, 2022, and becomes Apache 2.0 licensed four years after that date (i.e., 2.5 years from today), on October 18, 2026.
[0]: https://github.com/MaterializeInc/materialize/blob/76cb6647d...
Python's Substrait seems like the biggest/most-used competitor-ish out there. I'd love some compare & contrast; my sense is that Substrait has a smaller ambition, and more wants to be a language for talking about execution rather than a full on execution engine. https://github.com/substrait-io/substrait
We can also see from the DataFusion discussion that they too see themselves as a bit of a Velox competitor. https://github.com/apache/arrow-datafusion/discussions/6441
Project mention: Ask HN: How Can I Make My Front End React to Database Changes in Real-Time? | news.ycombinator.com | 2024-04-17- Some platforms like Supabase Realtime [3] and Firebase offer subscription models to database changes, but these solutions fall short when dealing with complex queries involving joins or group-bys.
My vision is that the modern frontend to behave like a series of materialized views that dynamically update as the underlying data changes. Current state management libraries handle state trees well but don't seamlessly integrate with relational or graph-like database structures.
The only thing I can think of is to implement it by myself, which sounds like a big PITA.
Anything goes, Brainstorm with me. Is it causing you headaches as well? Are you familiar with an efficient solution? how are you all tackling it?
[1] https://readyset.io/
Project mention: Error Handling for Large Rust Projects - A Deep Dive into GreptimeDB's Practices | dev.to | 2024-05-12**A good error report is not only about how it gets constructed, but what is more important, to tell what human can understand from its cause and trace. We call it Stacked Error.** It should be intuitive and you must have seen a similar format elsewhere like backtrace. From this log, it's easy to know the entire thing with full context, from the user-facing behavior to the root cause. Plus the exact line and column number of where each error is propagated. You will know that this error is *"from the query "blabla", the fifth package's header is corrupted"*. It's likely to be invalid user input and we may not need to handle it from the server side. This example shows the critical information that an error should contain: - **The root cause** that tells what is happening. - **The full context stack** that can be used in debugging or figuring out where the error occurs. - **What happens from the user's perspective.** Decide whether we need to expose the error to users. The first root cause is often clear in many cases, like the DecodeMessage example above, as long as the library or function we used implements their error type correctly. But only having the root cause can be not enough. Here is another [evidence](https://github.com/delta-incubator/delta-kernel-rs/pull/151) from Delta Lake developed by Databricks: 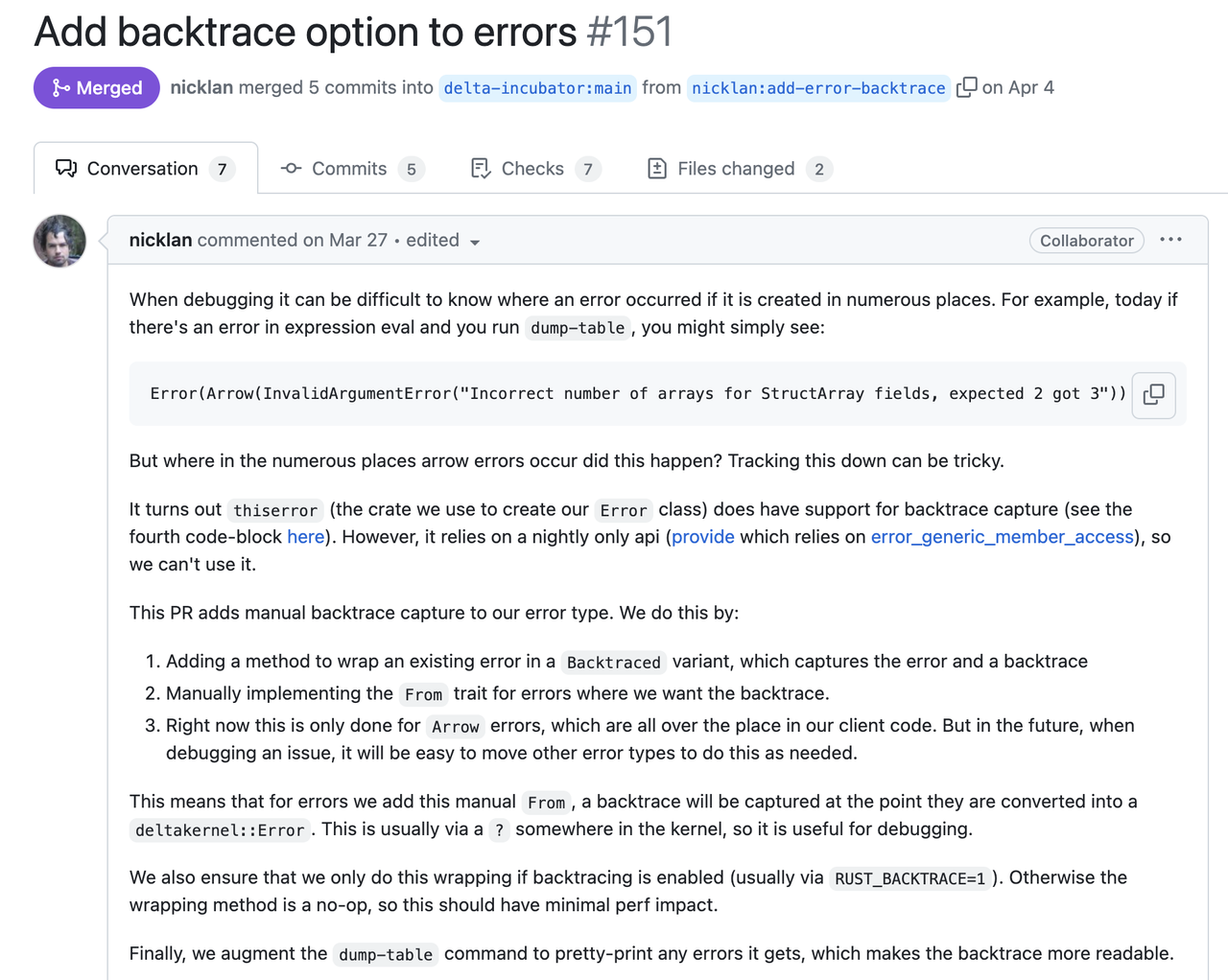 In the following sections, we will focus on the context stack and the way to present errors. And shows the way we implement it. So hopefully you can reproduce the same practices as in GreptimeDB. ### System Backtrace So, now you have the root cause (`DecodeMessage(serde_json: invalid character at 1)`). But it's not clear at which step this error occurs: when decoding the header, or the body? A intuitive thought is to capture the backtrace. `.unwrap()` is the first choice, where the backtrace will show up when error occurs (of course this is a bad practice). It will give you a complete call stack along with the line number. Such a call stack contains the full trace, including lots of unrelated system stacks, runtime stacks and std stacks. If you'd like to find the call in application code, you have to inspect the source code stack by stack, and skip all the unrelated ones. Nowadays, many libraries also provide the ability to capture backtrace on an `Error` is constructed. Regardless of whether the system backtrace can provide what we truly want, it's very costly on either CPU ([#1261](https://github.com/GreptimeTeam/greptimedb/pull/1261)) and memory ([#1273](https://github.com/GreptimeTeam/greptimedb/pull/1273)). Capturing a backtrace will significantly slow down your program, as it needs to walk through the call stack and translate the pointer. Then, to be able to translate the stack pointer we will need to include a large `debuginfo` in our binary. In GreptimeDB, this means increasing the binary size by >700MB (4x compared to 170MB without debuginfo). And there will be many noises in the captured system backtrace because the system can't distinguish whether the code comes from the standard library, a third-party async runtime or the application code. There is another difference between the system backtrace and the proposed Stacked Error. System backtrace tells us how to get to the position where the error occurs and you cannot control it, while the Stacked Error shows how the error is propagated. Take the following code snippet as an example to examine the difference between system backtrace and virtual stack: ```rust async fn handle_request(req: Request) -> Result { let msg = decode_msg(&req.msg).context(DecodeMessage)?; // propagate error with new stack and context verify_msg(&msg)?; // pass error to the caller directly process_msg(msg).await? // pass error to the caller directly } async fn decode_msg(msg: &RawMessage) -> Result { serde_json::from_slice(&msg).context(SerdeJson) // propagate error with new stack and context }
Project mention: Full-fledged APIs for slowly moving datasets without writing code | news.ycombinator.com | 2023-10-25
Hi, I'm the author of Supabase GraphQL (pg_graphql)
"Rusqlite is an ergonomic wrapper for using SQLite from Rust." - Crates.io
I think a lot of Ratatui apps will tend to land on similar concepts for your app. There's a few good examples of apps using a component approach rather than just widgets that I'm aware of:
- https://github.com/sxyazi/yazi
- https://github.com/TaKO8Ki/gobang
- https://github.com/nomadiz/edma
Perhaps the intuitive crate would make a good abstraction on top of Ratatui?
Project mention: GlueSQL v0.14 Release - Schemaless data support and the official doc website | /r/rust | 2023-05-30
NOTE:
The open source projects on this list are ordered by number of github stars.
The number of mentions indicates repo mentiontions in the last 12 Months or
since we started tracking (Dec 2020).
Rust SQL related posts
-
Why SurrealDB is the Future of Database Technology - An In-Depth Look
-
A tale of TimescaleDB, SQLx and testing in Rust
-
Squawk – A Linter for Postgres Migrations
-
OAuth and OIDC Implementation in SQL
-
Prolog language for PostgreSQL proof of concept
-
SQL is syntactic sugar for relational algebra
-
Introducing pgzx: create PostgreSQL extensions using Zig
-
A note from our sponsor - SaaSHub
www.saashub.com | 18 May 2024
Index
What are some of the best open-source SQL projects in Rust? This list will help you:
| Project | Stars | |
|---|---|---|
| 1 | surrealdb | 25,689 |
| 2 | cube.js | 17,214 |
| 3 | diesel | 12,020 |
| 4 | sqlx | 11,949 |
| 5 | prql | 9,470 |
| 6 | databend | 7,258 |
| 7 | risingwave | 6,366 |
| 8 | sea-orm | 6,364 |
| 9 | toydb | 5,912 |
| 10 | materialize | 5,598 |
| 11 | postgresml | 5,483 |
| 12 | datafusion | 5,200 |
| 13 | readyset | 3,896 |
| 14 | fselect | 3,828 |
| 15 | greptimedb | 3,835 |
| 16 | arroyo | 3,326 |
| 17 | rust-postgres | 3,312 |
| 18 | roapi | 3,098 |
| 19 | GQL | 3,057 |
| 20 | pg_graphql | 2,780 |
| 21 | rusqlite | 2,770 |
| 22 | gobang | 2,687 |
| 23 | gluesql | 2,609 |
Sponsored
SaaSHub - Software Alternatives and Reviews
SaaSHub helps you find the best software and product alternatives
www.saashub.com