
d2
TinyLlama
 Our great sponsors
Our great sponsors
| d2 | TinyLlama | |
|---|---|---|
| 92 | 13 | |
| 15,786 | 6,699 | |
| 3.1% | - | |
| 9.8 | 8.8 | |
| 4 days ago | 22 days ago | |
| Go | Python | |
| Mozilla Public License 2.0 | Apache License 2.0 |
Stars - the number of stars that a project has on GitHub. Growth - month over month growth in stars.
Activity is a relative number indicating how actively a project is being developed. Recent commits have higher weight than older ones.
For example, an activity of 9.0 indicates that a project is amongst the top 10% of the most actively developed projects that we are tracking.
d2
- NMAP-formatter: convert NMAP results to HTML, CSV, JSON, graphviz (dot), SQLite
- Penrose – Penrose
-
Pikchr: A PIC-like markup language for diagrams in technical documentation
While not embedded in markdown, I like d2 [1]. I can use it with org-babel to embed and view the diagrams on emacs. After using graphviz for years, the visual output seems more polished to me. With that said, I want to give pikchr a try.
- Ask HN: How do you build diagrams for the web?
-
Documentation as Code for Cloud - C4 Model & Structurizr
In the next post I'll deep-dive into the D2 language which also has a huge set of features. Stay tuned.
- Inkscape Cloud Architect
-
Nomnoml
That site is created by the maintainers of D2[1], so it might be biased, but I still think D2 has the friendliest syntax of the bunch, including nomnoml.
[1]: https://d2lang.com/
- Software Architecture Tools
- D2: Declarative Diagramming
-
Architecture diagrams enable better conversations
I've been using https://structurizr.com/ to automatically generate C4 diagrams from a model (rather than drawing them by hand). It works well with the approach for written documentation as proposed in https://arc42.org/. It's very easy to embed a C4 diagram into a markdown document.
The result is a set of documents and diagrams under version control that can be rendered using the structurizr documentation server (for interactive diagrams and indexed search).
I also use https://d2lang.com/ for declarative diagrams in addition to C4, e.g., sequence diagrams and https://adr.github.io/ for architectural decision records. These are also well integrated into structurizr.
TinyLlama
- FLaNK Stack Weekly 22 January 2024
-
TinyLlama: An Open-Source Small Language Model
GitHub repo with links to the checkpoints: https://github.com/jzhang38/TinyLlama
-
NLP Research in the Era of LLMs
> While LLM projects typically require an exorbitant amount of resources, it is important to remind ourselves that research does not need to assemble full-fledged massively expensive systems in order to have impact.
Check out TinyLlama; https://github.com/jzhang38/TinyLlama
Four research students from Singapore University of Technology and Design are pretraining a 1.1B Llama model on 3 trillion token using a handful of A100's.
They're also providing the source code, training data, and fine-tuned checkpoints for anyone to run.
-
TinyLlama - Any news?
The first one was that the minimum learning rate was mistakenly set to the same value as the maximum learning rate in cosine decay, so the learning rate wasn't decreasing. This was discovered relatively early during training and discussed in this issue: https://github.com/jzhang38/TinyLlama/issues/27
-
Llamafile lets you distribute and run LLMs with a single file
Which is a smaller model, that gives good output and that works best with this. I am looking to run this on lower end systems.
I wonder if someone has already tried https://github.com/jzhang38/TinyLlama, could save me some time :)
- FLaNK Stack Weekly for 20 Nov 2023
- New 1.5T token checkpoint of TinyLLaMa got released!
-
What Every Developer Should Know About GPU Computing
I thought I'd share something with my experience with HPC that applies to many areas, especially in the rise of GPUs.
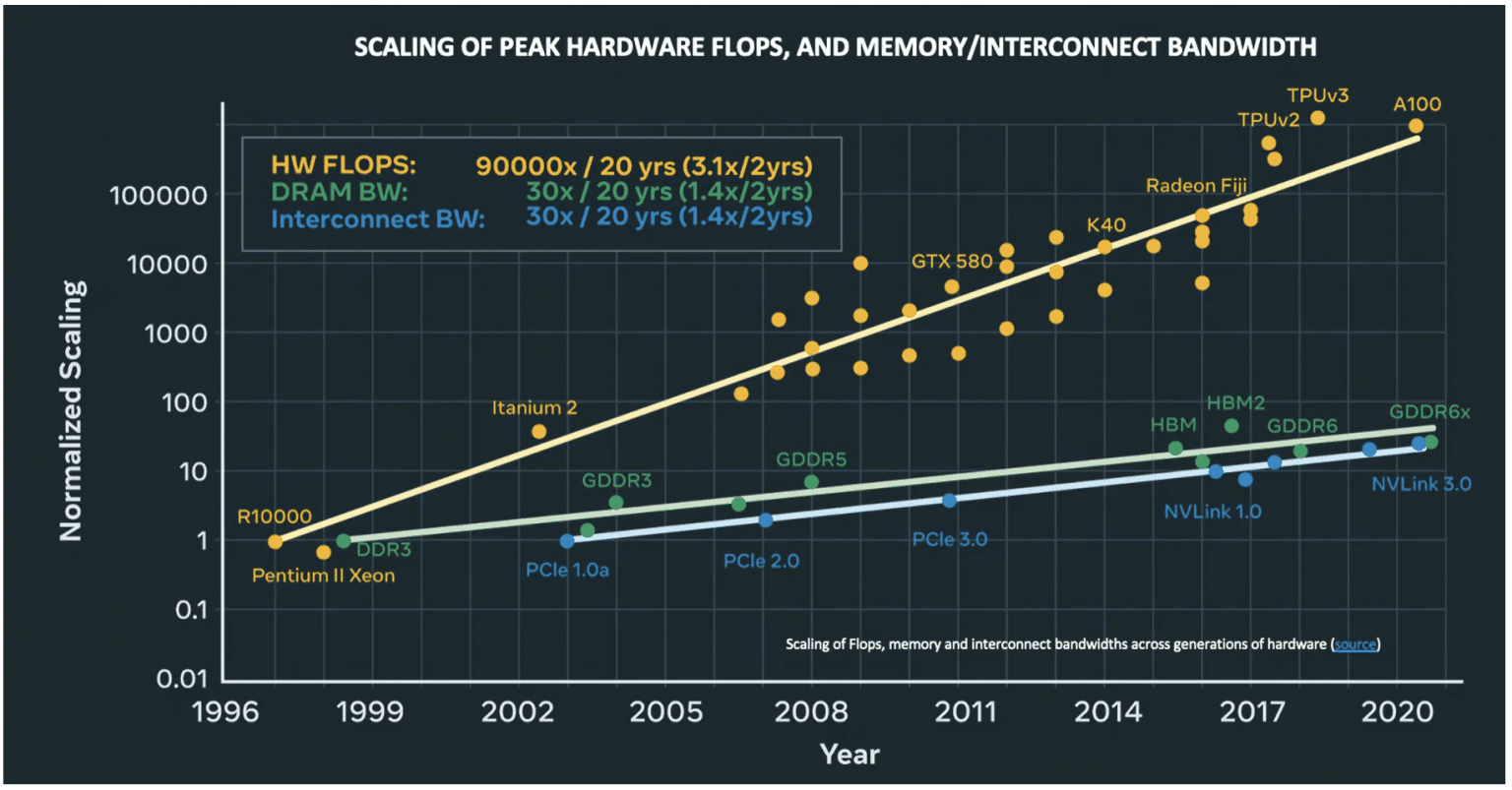
The main bottleneck isn't compute, it is memory. If you go to talks you're gonna see lots of figures like this one[0] (typically also showing disk speeds, which are crazy small).
Compute is increasing so fast that at this point we finish our operations long faster than it takes to save those simulations or even create the visualizations and put on disk. There's a lot of research going into this, with a lot of things like in situ computing (asynchronous operations, often pushing to a different machine, but needing many things like flash buffers. See ADIOS[1] as an example software).
What I'm getting at here is that we're at a point where we have to think about that IO bottleneck, even for non-high performance systems. I work in ML now, which we typically think of as compute bound, but being in the generative space there are still many things where the IO bottlenecks. This can be loading batches into memory, writing results to disk, or communication between distributed processes. It's one beg reason we typically want to maximize memory usage (large batches).
There's a lot of low hanging fruit in these areas that aren't going to be generally publishable works but are going to have lots of high impact. Just look at things like LLaMA CPP[2], where in the process they've really decreased the compute time and memory load. There's also projects like TinyLLaMa[3] who are exploring training a 1B model and doing so on limited compute, and are getting pretty good results. But I'll tell you from personal experience, small models and limited compute experience doesn't make for good papers (my most cited work did this and has never been published, gotten many rejections for not competing with models 100x it's size, but is also quite popular in the general scientific community who work with limited compute). Wfiw, companies that are working on applications do value these things, but it is also noise in the community that's hard to parse. Idk how we can do better as a community to not get trapped in these hype cycles, because real engineering has a lot of these aspects too, and they should be (but aren't) really good areas for academics to be working in. Scale isn't everything in research, and there's a lot of different problems out there that are extremely important but many are blind to.
And one final comment, there's lots of code that is used over and over that are not remotely optimized and can be >100x faster. Just gotta slow down and write good code. The move fast and break things method is great for getting moving but the debt compounds. It's just debt is less visible, but there's so much money being wasted from writing bad code (and LLMs are only going to amplify this. They were trained on bad code after all)
[0] https://drivenets.com/wp-content/uploads/2023/05/blog-networ...
[1] https://github.com/ornladios/ADIOS2
-
Mistral 7B Paper on ArXiv
As discussed in the original GPT3 paper (https://twitter.com/gneubig/status/1286731711150280705?s=20)
TinyLlama is trying to do that for 1.1B: https://github.com/jzhang38/TinyLlama
As long as we are not at the capacity limit, we will have a few of these 7B beats 13B (or 7B beats 70B) moments.
- TinyLlama training to 500B tokens is complete
{kind=link}
What are some alternatives?
mermaid - Generation of diagrams like flowcharts or sequence diagrams from text in a similar manner as markdown
langchain - 🦜🔗 Build context-aware reasoning applications
C4-PlantUML - C4-PlantUML combines the benefits of PlantUML and the C4 model for providing a simple way of describing and communicate software architectures
public - A collection of my cources, lectures, articles and presentations
d3 - Bring data to life with SVG, Canvas and HTML. :bar_chart::chart_with_upwards_trend::tada:
text-generation-webui - A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models.
Mermaid - Edit, preview and share mermaid charts/diagrams. New implementation of the live editor.
llamafile - Distribute and run LLMs with a single file.
diagrams - :art: Diagram as Code for prototyping cloud system architectures
ADIOS2 - Next generation of ADIOS developed in the Exascale Computing Program
mermaid-cli - Command line tool for the Mermaid library
airoboros - Customizable implementation of the self-instruct paper.